すぐできる!特徴量の相関を調べる&可視化
本ページにはプロモーションが
含まれていることがあります

「データサイエンスもくもく会」を10月から開始し、皆さんのおかげで、5回を開催することができました。もくもく会とは、毎回異なるトピックで講義し、ディスカッションする、無料オンライン・サロンです。ライブイベントの他に講師や参加者同士が常に繋がりを持つSlackコミュニティもあります。
参考:https://gri.jp/media/entry/2409
年内最終回のもくもく会(2021.12.16)では、特徴量の重要さ、および特徴量エンジニアリングについて話しました。参加者様から数多くの質問をいただきまして、(可能の限り)回答させていただいたものが下記の記事です。
本記事では、そのうちの1つの質問に関連する「特徴量間の相関の可視化」について解説していきます。
読むだけでもイメージを持てますが、Jupyter Notebook上でコードを再現するとさらに身につきます!

資料請求でデータサイエンスの基礎が学べる講義を無料プレゼント
・講座(G検定・機械学習・データ分析など) 約3時間分
現役プロ講師によるわかりやすい講義
1分で簡単!今すぐ見れます(会員登録→お申込み→講座視聴)
(準備)演習に使うデータを読み込む
今回の演習では、scikit-learnで提供されている公開サンプルデータセットを使います。
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html
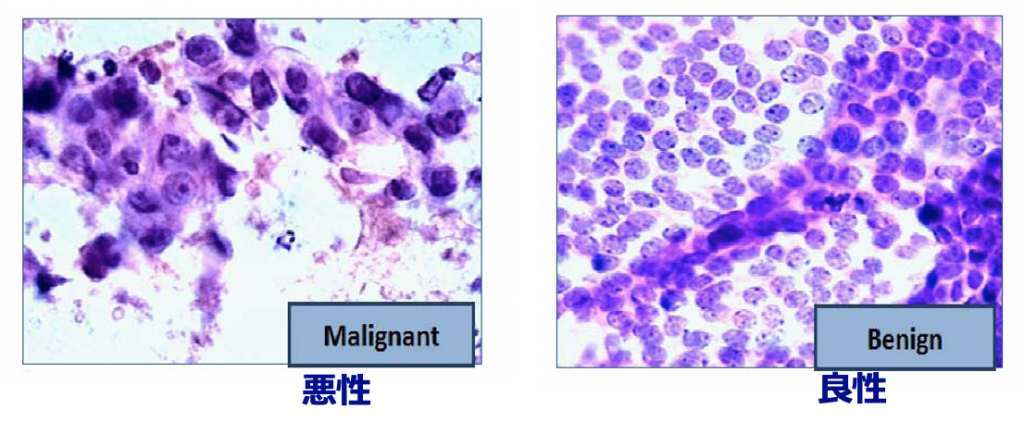
一言でいうと、腫瘍細胞の形状に関する情報を数値化したデータです。
- 穿刺吸引細胞診断法で生成されたデジタル画像から特徴量を算出
- 特徴量を構造化(表形式)データとして保持し、機械学習に利用しやすくしています
- 569件(悪性212件、良性357件)
- 30個の特徴量(細胞の半径・周長・面積など)
Pandasを用いてデータを読み込み、DataFrameに納め、基礎情報を観察します。

念のため、データに欠損値がないことを確認し、target(悪性か良性か)の値の種別も確認します。
“target”には、0(悪性)と1(良性)の2種類があり、良性が若干多いけど、さほどバランスが悪いわけでもなさそうですね。

相関関係を計算する
30個の特徴量(列)があり、同士の相関を調べるのに、30×30は多すぎて見づらいので、DataFrameを分割しておきます。
特徴量には平均(mean)、最大(worst)、誤差(error)の3種類があるので、この基準で分割し、種類ごとに相関を見た方がいいでしょう。
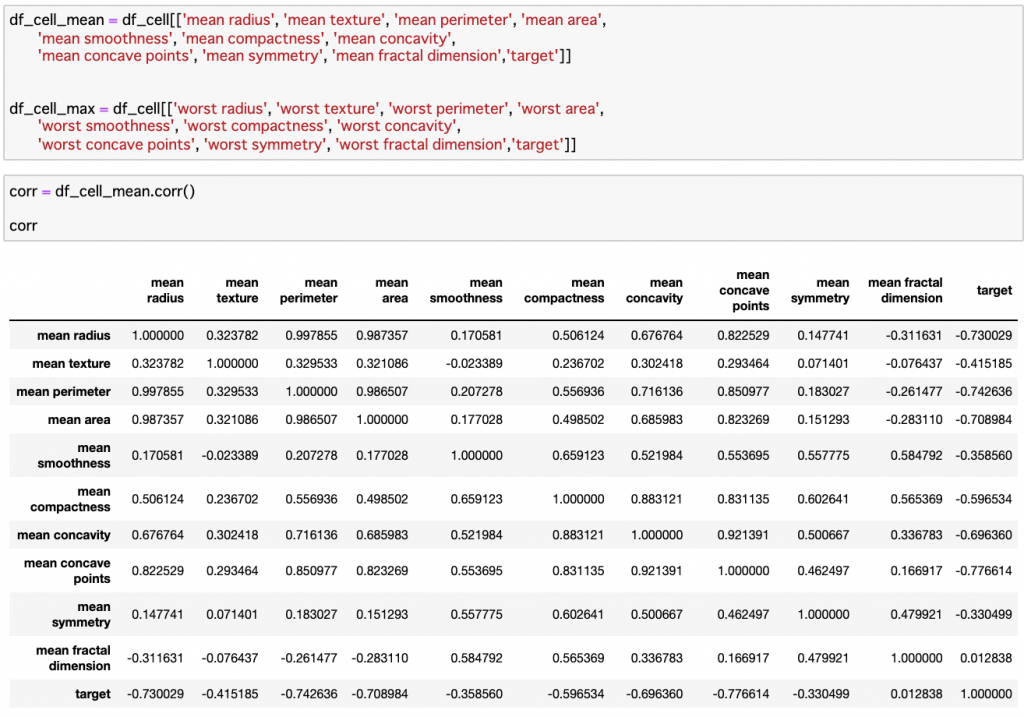
上記は、DataFrameを分割後、細胞の半径、面積、周長などに関する「平均値」の10個の特徴量について、相関係数を算出した結果です。同時にtarget(予測したい変数)との関連性も見ることができます。
相関関係を可視化する
次に、上記で計算した相関係数をビジュアル的にさらにわかりやすくする工夫をしましょう。
2種類の可視化を行います。1つは散布図を描くことです。もう1つはseabornという可視化パッケージでヒートマップを作ることです。
Matplotlibを使うので、importし、inlineマジックコマンドをしておきます。

また、scatter_matrixという散布図を描くのに必要なクラスも入れておきます。
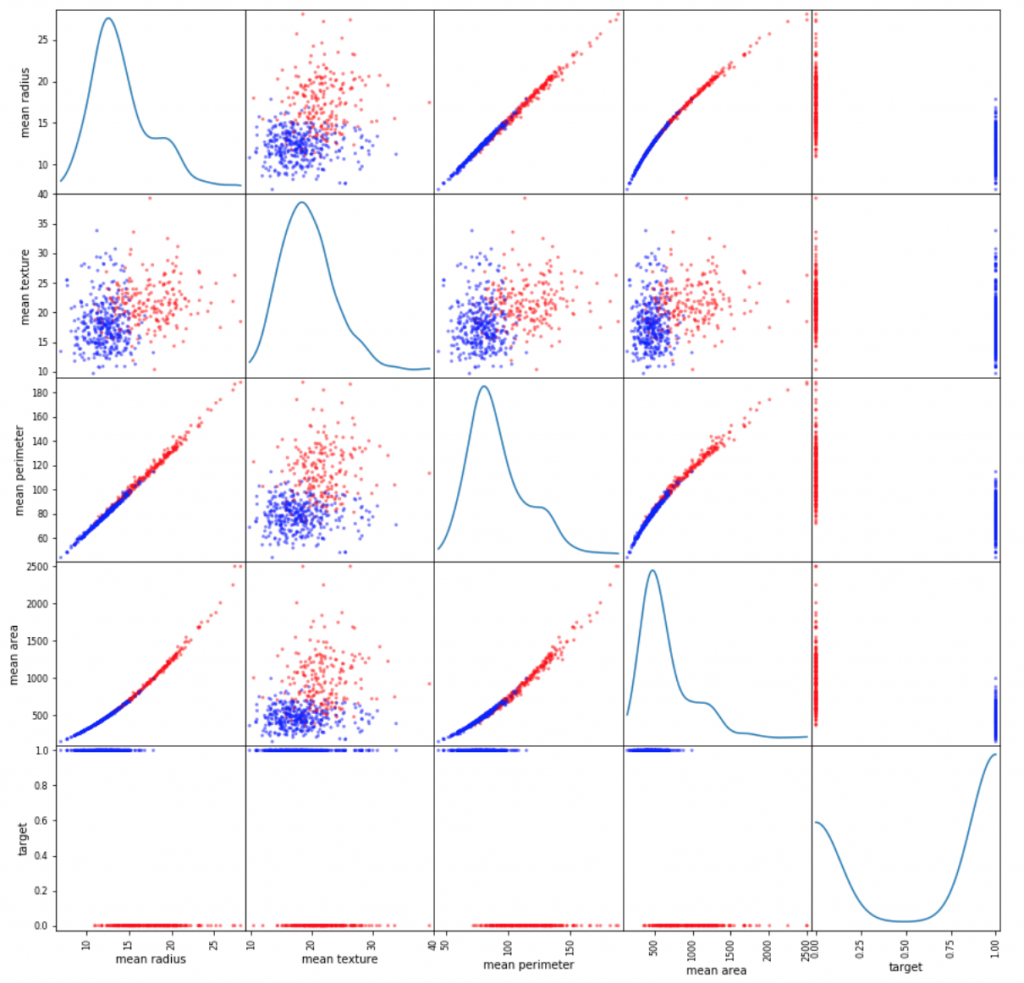
下のコードは、target列の情報に対し悪性を赤、良性を青色と区別させて、5つのmean特徴量について、散布図を描かせています。

結果は以下となります。
対角線上(同じ特徴量同士)のプロットは分布を表し、”target”vs特徴量(5行目)からは、「予測したい対象と特徴量の関係性」に関するヒントが得られます。その他のプロットは、特徴量間の関係性、つまり相関の強さを表します。これが、https://gri.jp/media/entry/3758 の中で解説しているMulticollinearity問題(マルコチ問題)と関連します。
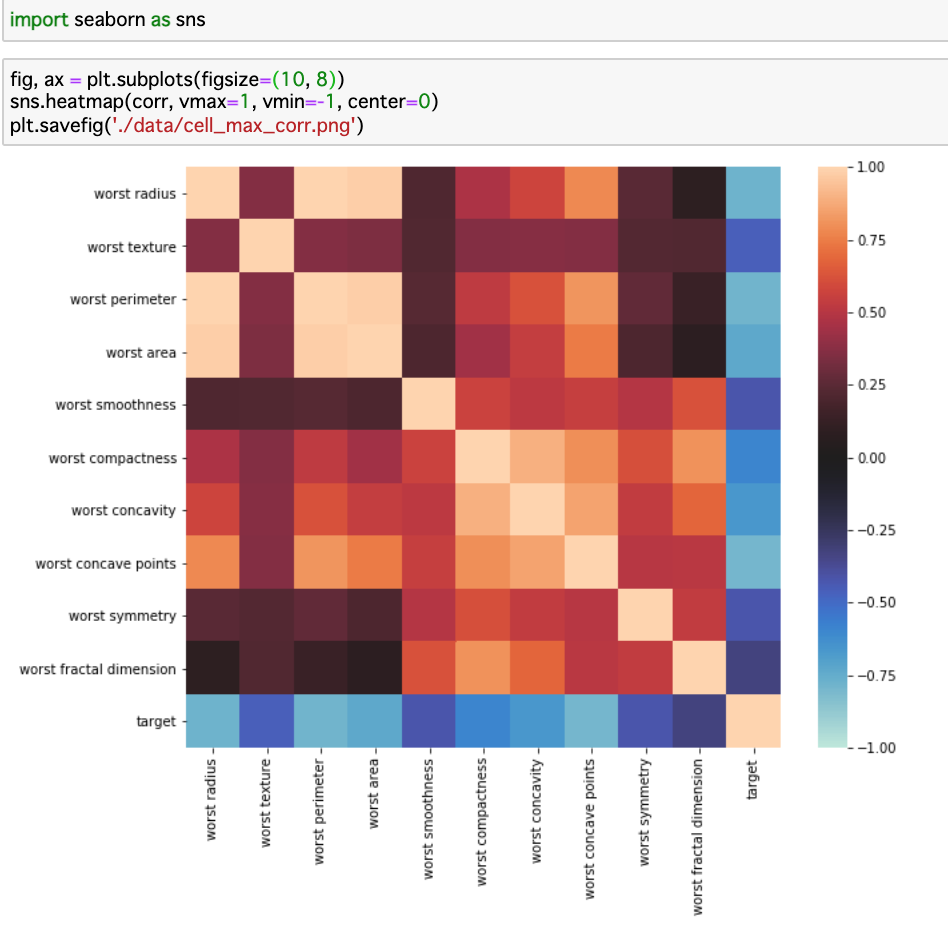
次に、ヒートマップの方を作ってみましょう。
下図は、先ほど計算した “corr” という相関係数の行列をインプットとしています。先ほどは平均値(mean)の10個の特徴量について算出していましたが、今回は最大値(worst)について”corr”を計算し直してから、ヒートマップ化しました。
ちょっとした宿題
本記事は、特徴量間の相関を計算し、可視化するための手法を伝えています。ここで得られた結果をもとに、詳しい考察は各自やってみてください。例えば…
「半径と面積は相関が強そうなので、機械学習モデルを構築する際には、○○を特徴量に含ませて、◎◎を同時に入れない方がいい」
上記のように、共重線形性を防ぐ観点で、効果的な予測を行う観点で考察をしてみてください。
機械学習モデルの構築を実践できる講座
Pythonを用いて、データ処理の基本や機械学習の活用を学びたい方のために、レベル別に2種類の講座をアガルートアカデミーでご用意しております。
業務現場で使える機械学習の技術を短時間で、効率的に身につけるための講座として最適です。ぜひご活用ください。
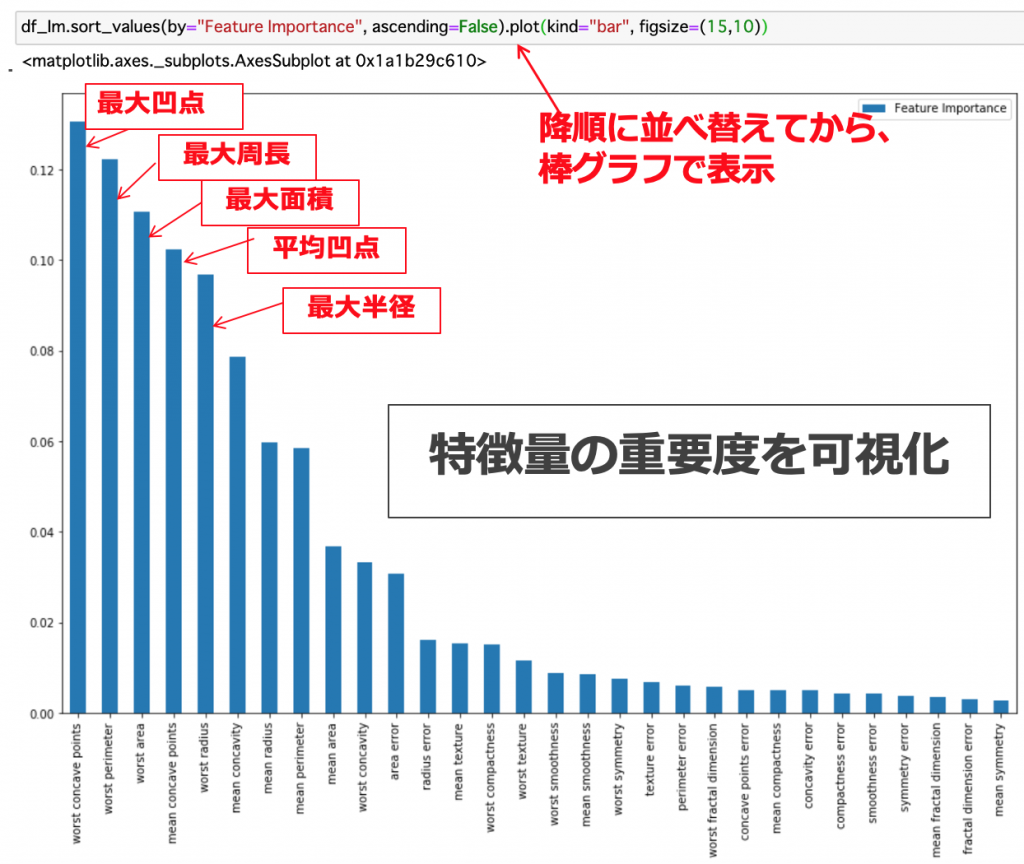
(補足)本記事では詳しいコードを載せていませんが、他にデータを使って、ランダムフォレスト(RandomForest)などの機械学習を用いた予測モデルを訓練した後に、scikit-learnパッケージの機能を使って、実際に各特徴量がどれくらい予測したいもの(”target”)に寄与したのかを推測することができます。
関連記事
https://www.sbbit.jp/article/cont1/76066
資料請求でデータサイエンスの基礎が学べる講義を無料プレゼント
・講座(G検定・機械学習・データ分析など) 約3時間分
現役プロ講師によるわかりやすい講義
1分で簡単!今すぐ見れます(会員登録→お申込み→講座視聴)
実践的な
Python・データ分析スキル
を身に付けたい方へ
何から手をつけたら良いかわからない
独学で挫折したことがある
専門的な内容で身近に相談できる人がいない
このような悩みをお持ちでしたら
AI Academy Bootcampにご相談下さい!


この記事の著者 ヤン ジャクリン
2015年 東京大学大学院 理学系研究科物理学専攻 修了(理学博士)
2015年 高エネルギー加速器研究機構 素粒子原子核研究所(博士研究員)
2017年 株式会社GRI(現職) 講師 兼 分析官
2019年 Tableau Desktop Certified Associate 資格取得
・英検1級
・TOEFL IBT試験満点
北京生まれ、米国東海岸出身(米国籍)、小学高学年より茨城県育ち。
万物の質量の源となるヒッグス粒子の性質を解明し、加速器実験による新粒子発見に関する研究を行い、国際・国内学会発表20件以上、査読論文5件以上。
10年以上に渡り、幅広い年齢層の学習指導を学習塾や大学などで実施(5科目、英会話、受験指導、素粒子物理など)。
現在は、株式会社GRIにて、データ分析官(データ前処理、可視化分析、マーケティング施策の分析 他)
公開講座および法人研修を多数開設。



