説明可能AI(Explainable AI; XAI)
本ページにはプロモーションが
含まれていることがあります

AI・データサイエンス、機械学習の
実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データアナリストを目指したい
- AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを
無料体験してみませんか?

無料で120以上の教材を学び放題!
理解度を記録して進捗管理できる!
テキストの重要箇所にハイライトを残せる!
割引クーポンやsale情報が届く!
1分で簡単!無料!
▶無料体験して特典を受け取る
40時間以上の動画講座が見放題!
追加購入不要!これだけで学習できるカリキュラム
(質問制度や添削プラン等)充実したサポート体制!
▶AI人材コースを見る
なぜモデルの解釈性が重要なのか
画像認識、音声認識、自然言語処理など数多くの分野でブレークスルーをもたらしたディープラーニング技術の元となるアルゴリズムは、ニューラルネットワークです。
ニューラルネットワークは、従来の機械学習モデルに比べて特徴量エンジニアリングのコストが軽減され、そして、非常に高い識別能力と表現力を発揮することが特徴です。一方で、問題視されているのは、モデルの判断の根拠が解釈しにくいことです。これは「ブラックボックス問題」と呼ばれ、AI技術の社会への適用を難しくしている要因の1つです。
機械学習全般の問題ではあるものの、ニューラルネットワークでは特にブラックボックス性が高いです。一般的に、複雑なモデルほど説明が難しいです。例えば、ニューラルネットワークは比較的シンプルな決定木よりも「複雑なモデル」といえます。
「モデルが何を根拠にそのような予測や判断をしたのか」を説明できていないと、そのモデルを導入しているサービスやアプリケーションの利用者が不安を感じてしまいます。これは高リスク分野、つまり利用者の健康安全や個人情報に関与する分野では特に深刻です。
例えば、「AI による医療診断の結果、腫瘍は悪性ですが、AI がそう判断した根拠はわかっていません」と言われた場合、診断の結果が大変受け入れにくいものになります。あるいは、仮に奨学金の審査が機械学習モデルを用いて行われるとすれば、奨学金申請を受入または拒否の判断の根拠を説明する必要が法律から求められるのでしょう。
いずれにしても、開発者が利用者に十分に納得できる説明を提供できないと、AIの利用に同意してもらえず、AI技術全般への不信感につながりかねないです。
モデルの解釈を目指した研究
ブラックボックス性はAIの社会実装を著しく阻止する要素になっているため、近年ではAI・機械学習モデルの解釈性に着目した研究が増えています。出力結果に至った経緯や判断の根拠も説明できるAIは、Explainable AI (説明可能AI)、略して XAIと一般的に呼ばれています[1]。
XAIの技術は画像などの非構造化データと構造化データ(「表形式データ」英表記:tabular data”とも呼ばれる)の両方に適用できるものがあります。
表形式データの場合は、売上予測や行動予測に対する各特徴量(価格、位置、人物の属性など)の寄与の重要度を導き出すことが例として挙げられます。画像データの場合は、画像分類の根拠をピクセルレベルで可視化するような用途が多いです。
ここ数年、XAI(説明可能AI)に関する論文の数がますます増えています。NeurIPS だけで見ても2020年以降により最先端の解釈手法の研究が進出しています。
最近では、強化学習における行動の最適化のパターンなど、XAIの適用範囲が広げられています。他に、既存するXAIの限界を明らかにすることによって、「モデルの解釈手法に対するさらなる解釈と警戒」という視点から出された論文も見られます。 本レポートの前半では、XAI技術のアプローチを俯瞰し、後半ではいくつかの論文を取り上げてより詳細に解説していきます。
[1] XAIの概念は、米国のDARPA(国防高等研究計画局)が主導する研究プロジェクトが発端となっています。
XAIのアプローチの種別
モデルの解釈に使われる代表的な手法を紹介します。 大きく分けて、局所的な説明 (local surrogate)と大域的な説明 (global surrogate)の2種のアプローチがあります。
局所的な説明
モデル全体の傾向ではなく、特定の入力データサンプルとそれに対する予測結果に着目して、判断根拠を解釈と可視化をします。
具体的には、複雑なモデルを単純かつ可読性の高い線形モデルで近似することで予測に寄与する因子を推定します。例えば、表形式データの場合「今回の予測にどの変数が特に効いたのか」を、画像データの場合「この画像のどの部分が予測に効いたのか」を算出します。モデル全体を近似するとかえって複雑で分かりにくくなることがあるので、あえて1つのサンプルだけの予測結果に着目して解釈を提供することがポイントです。ここから「局所的」の名称が由来します。
局所的な説明の代表的な技術の1つは、LIME (Local Interpretable Model-agnostic Explanations) です。
原論文: ”Why Should I Trust You? Explaining the Predictions of Any Classifier”
https://arxiv.org/abs/1602.04938
図1 に LIME を用いた要因解析の流れが示されています。 以下のような流れで、単純で解釈しやすい線形回帰モデルを用いて、複雑なモデルを近似することで解釈を行っています。
1解釈したい難解な予測モデルに、1件のデータを入力し、1つの予測結果を得る。
2. 予測結果に対してのみ局所的に近似するような予測結果を出す単純な予測モデル(線形回帰モデル)を作る。
3 単純なモデルから予測に強く効いた特徴量を選び解釈を行うことで、難解なモデルの方を解釈したことと見なす。
上記の2では、モデルが受け取るデータの周辺のデータ空間に対して、サンプリングを繰り返し行うことで集められたデータセットを教師として、近似用の線形回帰モデルを学習しています。このプロセスによって、対象サンプルの周囲のデータ空間でのみ有効な近似モデルを獲得します。局所的に留めることで、近似の誤差を許容範囲内 に収めていると解釈することができます。

大域的な説明
大域的な説明では、モデル全体に注目しながら、各特徴量の寄与度を調べて、予測根拠を解釈しようとします。
大域的な解釈ツールの代表は Grad-CAMです。
原論文: https://arxiv.org/pdf/1610.02391v1
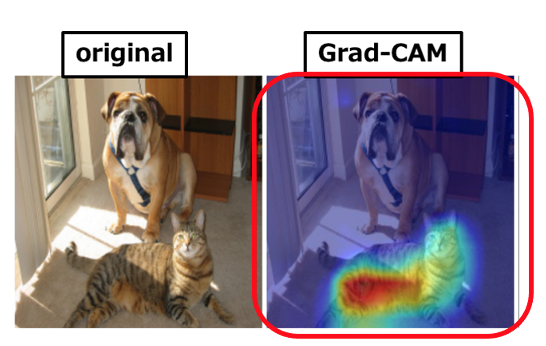
Grad-CAM は、CNNモデル全体に対する予測根拠を可視化するための手法です。Grad-CAMの名前には “Gradient”、つまり「勾配情報」に由来します。CNNモデルが画像分類を行う際に使用する勾配情報を活用し、画像認識モデルそのものに判断根拠を持たせようとします。 その発想としては、勾配が大きいピクセルは予測クラスの出力に大きく影響すると判断して、ピクセルに重みを割り振ります[1]。
CNNが分類のために注視していると推定される範囲を、ヒートマップで表示することができます。図2はGrad-CAM を適用し可視化している例です。ヒートマップから、画像のどの部分を根拠に猫を認識しているのか、そして、モデルが正しく猫を認識していることを目視で確認できます。
重要なポイントは、LIMEなどは個別の入力データに対して、その結果を別の単純なモデルで近似していくアプローチであるのに対し、Grad-CAMは、ディーププラーニングのモデルそのものに判断根拠を持たせる手法であることです。
[1] 最後の畳み込み層の予測クラスの出力値に対する勾配が用いられます。
参考文献
人工知能学会:機械学習における解釈性(Interpretability in Machine Learning)
AI・データサイエンス、機械学習の
実践力を高めたい方へ
- プログラミングを0から学びたい
- データサイエンティスト、データアナリストを目指したい
- AIエンジニア、大規模言語モデル(LLM)エンジニアを目指したい
AI人材コースを
無料体験してみませんか?
無料で120以上の教材を学び放題!
理解度を記録して進捗管理できる!
テキストの重要箇所にハイライトを残せる!
割引クーポンやsale情報が届く!
1分で簡単!無料!
▶無料体験して特典を受け取る
40時間以上の動画講座が見放題!
追加購入不要!これだけで学習できるカリキュラム
(質問制度や添削プラン等)充実したサポート体制!
会員20万人突破記念!
全商品5%OFF!

この記事の著者 ヤン ジャクリン
2015年 東京大学大学院 理学系研究科物理学専攻 修了(理学博士)
2015年 高エネルギー加速器研究機構 素粒子原子核研究所(博士研究員)
2017年 株式会社GRI(現職) 講師 兼 分析官
2019年 Tableau Desktop Certified Associate 資格取得
・英検1級
・TOEFL IBT試験満点
北京生まれ、米国東海岸出身(米国籍)、小学高学年より茨城県育ち。
万物の質量の源となるヒッグス粒子の性質を解明し、加速器実験による新粒子発見に関する研究を行い、国際・国内学会発表20件以上、査読論文5件以上。
10年以上に渡り、幅広い年齢層の学習指導を学習塾や大学などで実施(5科目、英会話、受験指導、素粒子物理など)。
現在は、株式会社GRIにて、データ分析官(データ前処理、可視化分析、マーケティング施策の分析 他)
公開講座および法人研修を多数開設。



