近年注目のニューラル機械翻訳について!機械翻訳システムの仕組みを探る
本ページにはプロモーションが
含まれていることがあります

現代では翻訳機能を持ったWebサービスやアプリなども登場し、非常に便利になりました。
しかもその精度も年々向上し、人が翻訳したかのようなレベルに到達しつつあります。
その背景には機械翻訳システムがあるのですが、これは自然言語処理を行う代表的なシステムの一種で、段階的にこれまで進化を遂げてきました。
大別すると3種あり、ここではそれら機械翻訳の手法を紹介するとともに、近年登場した「ニューラル機械翻訳」に関して詳しく解説していきます。
AI・データサイエンス、機械学習の
実践力を高めたい方へ
- AI・データサイエンス・LLMアプリについて知りたい
- AIエンジニア、データサイエンティストになりたい
- DX化推進のための知識を身につけたい
AI人材コースを
無料体験してみませんか?

自分のスキルに合わせたカリキュラムが生成できる!
理解度を記録して進捗管理できる!
テキストの重要箇所にハイライトを残せる!
1分で簡単!無料!
▶無料体験して特典を受け取る
追加購入不要!これだけで学習できるカリキュラム
充実のサポート体制だから安心
購入特典で2万円相当の基本講座をプレゼント!
▶AI人材コースを見る
代表的な機械翻訳システム3種
翻訳の仕組みは近年登場したわけではありません。数十年以上前から存在していました。
しかしその精度は現代ほど高くなく、それ故用途も限定的でした。
IT等の発展に伴いその精度は徐々に進化していきますが、常に一定の成長曲線で進化していくわけではありません。
革新的な技術が登場すれば飛躍的に進化を遂げることができます。
以下ではこれまでの機械翻訳システムに関して、順を追って紹介していきます。
ルールベース機械翻訳
AIが登場した当初と同じように、機械翻訳にも昔はルールベースの手法が用いられていました。
この手法においては、2つの言語に関するマニュアルを人が事前に作成しておかなくてはなりません。
そのマニュアルに沿って照合し、訳文を出力するのです。
例えば構文のルール、単語の意味を両言語に対応させた辞書などを実装します。
この場合、膨大な量のルールの登録、複雑なルールの登録が大変という難点を抱えていました。
統計的機械翻訳
1980年代後半からはルールベースに代替する手法がいくつか提案されるようになり、その過程で登場したのが統計的機械翻訳です。
統計モデルの学習を経て訳文を出力する仕組みでできており、1990年代にはこの手法が主流となりました。
逐一ルールを設定することなく、データを使ってシステムが学習できるようになったのです。
両言語における文章のペアを大量に集め、これを学習データとして用います。
そうしてこれらのペアを結びつける確率テーブルを算出し、新たな文章の入力を受けたときには学習済み確率テーブルを参照して翻訳文を探します。
Google翻訳でも、2016年までの10年間、この手法が採用されていました。
ニューラル機械翻訳
続いて紹介するニューラル機械翻訳は、近年登場し、期待を寄せられているシステムです。
2016年、この仕組みを用いた「GNMT(Google Neural Machine Translation)」がGoogleから発表され注目を集めました。
当該システムには、RNN(リカレントニューラルネットワーク)の対から構成されるエンコーダ・デコーダモデルが組み込まれています。
翻訳においては系列の長さが異なるものへの変換が求められるため、符号化を行うエンコーダ、復号化を行うデコーダを持つネットワークが必要になります。
エンコーダが原文を読み込み、埋め込み層と呼ばれる層で分散表現に変換、入力の意味を捉え、特徴表現へと隠れ層で変換、活性化値をデコーダに渡します。
デコーダにより訳文を出力します。
このシステムにより精度はさらに向上し、最近ではGoogle以外でもニューラル機械翻訳が用いられるようになっています。
ニューラル機械翻訳はどのような仕組みで翻訳しているのか
ニューラル機械翻訳について、もう少しその翻訳の仕組みを見ていきましょう。
エンコーダ・デコーダモデルとは?
近年の言語モデルの多くにRNNが用いられています。
RNNはフィードバック機構を持ち、文章の変換に必要な、時系列データの処理ができるからです。
そして自然言語処理においては、RNNを用いた「sequence-to-sequence(Seq2Seq)」と呼ばれるモデルが使われます。
Seq2Seqはエンコーダとデコーダの、2つのRNNから構成されるため「エンコーダ・デコーダモデル」と呼ばれるのです。
エンコーダで入力データが符号化され、符号化された情報をデコーダの方で複元しています。
ただ、出力データも時系列であることから一気に出力をすることはできません。
そこで時系列の次のステップにおいては、デコーダは自らの出力を入力として受け取りつつ、1つずつ処理していくことになります。
つまりフィードバックしながら出力を組み立てていくのです。
機械翻訳の流れ
「ある女性は彼女の猫を抱えています」という意味である”A woman is carrying her cat”(英語)を、”Une femme tient son chat”(フランス語)に翻訳していく流れを見ていきましょう。
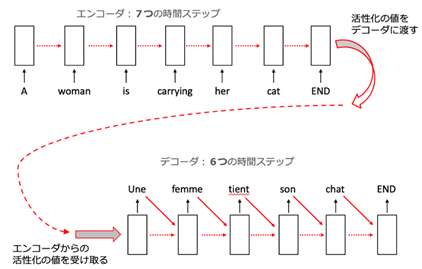
図の白い長方形は、連続的な時間ステップで処理するエンコーダとデコーダを表しています。
図の上部にあるように、入力はEND符号を含め7つの時間ステップでエンコードされます。
点線の矢印は隠れ層における再帰型の繋がりを表します。
単語を1つずつ隠れ層の活性化値としてエンコードし、次のユニットに送っていくことで原文を表すものが作られていきます。
END符号が付与されると、隠れ層の活性化値が文章全体のエンコードの結果として図下部のデコーダ・ネットワークへ送られます。
原文の解釈ができれば、続いて翻訳文を作り始めます。フィードバックを繰り返しつつ作成され、また、入力のステップ数とは異なる出力をすることもできます。
この例でも英語では入力が7個であったのに対し、フランス語は出力が6個となっています。
このように、エンコーダ・デコーダモデルだと理論上は文章の長さに関係なく翻訳ができます。
ただ実際は翻訳前の文章が長くなりすぎると先頭の情報を「忘れる」という現象が起こってしますので、長い文章に対する翻訳には工夫が必要になるでしょう。
関連記事:E資格とは?合格率(合格点)・難易度や本当に「意味がない」のかも解説
まとめ
代表的な機械翻訳システム3種
- ルールベース機械翻訳
- 統計的機械翻訳
- ニューラル機械翻訳
ニューラル機械翻訳はどのような仕組みで翻訳しているのか
- エンコーダ・デコーダモデルとは?
- 機械翻訳の流れ
AI・データサイエンス、機械学習の
実践力を高めたい方へ
- AI・データサイエンス・LLMアプリについて知りたい
- AIエンジニア、データサイエンティストになりたい
- DX化推進のための知識を身につけたい
AI人材コースを
無料体験してみませんか?
自分のスキルに合わせたカリキュラムが生成できる!
理解度を記録して進捗管理できる!
テキストの重要箇所にハイライトを残せる!
1分で簡単!無料!
▶無料体験して特典を受け取る
追加購入不要!これだけで学習できるカリキュラム
充実のサポート体制だから安心
購入特典で2万円相当の基本講座をプレゼント!
▶AI人材コースを見る



